在做技术 SEO 时,有一个文件被称为网站的“看门人”,它就是 Robots.txt。
很多新手对它知之甚少,甚至完全不敢碰它。这种谨慎是对的。因为在 SEO 圈子里流传着这样一句话:“如果你不懂 Robots 协议,最好的操作就是不要动它。”
为什么?因为只要你在里面写错一行代码,Google 的爬虫就会被你拒之门外,你的网站收录量可能会瞬间归零。
今天这篇,我就用大白话带大家看懂 Robots.txt 的运作原理,以及对于我们“一人公司”来说,如何安全地管理这个“生死门”。
一、 什么是 Robots.txt?(君子协定)
Robots.txt 是一个存放在你网站根目录下的纯文本文件。
它的作用是“指挥交通”。它告诉 Google、Bing 这些搜索引擎的爬虫(Spider):
- 哪些房间(页面)你可以进?
- 哪些房间(后台、购物车)你不能进?
注意: 这是一份“君子协定”。Google 这种正规搜索引擎会遵守它,但恶意的爬虫或黑客是不会理会它的。所以,不要试图用它来保护隐私数据。
二、 为什么要设置它?(节省预算)
既然我们希望 Google 收录越多越好,为什么还要屏蔽一部分页面呢?
这涉及到 SEO 的一个进阶概念:抓取预算(Crawl Budget)。
Google 给每个网站分配的爬虫精力是有限的。如果你的网站很大(几万个页面),你肯定不希望爬虫把时间浪费在“后台登录页”、“购物车页”、“搜索结果页”这些对排名没用的页面上。
通过 Robots.txt 屏蔽这些无用页面,能让 Google 把精力集中在抓取你的核心文章和产品页上。
对于刚起步的小网站(几百个页面以内),其实不用太纠结抓取预算。只要没有严重的错误,默认设置就足够了。
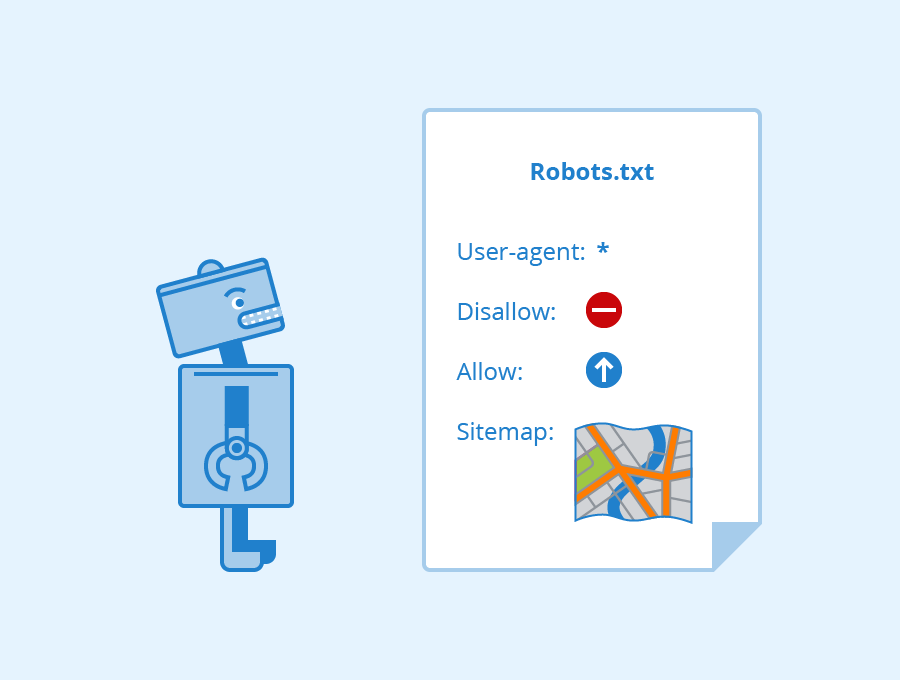
三、 读懂 4 个核心指令
打开任何一个网站的 Robots 文件(例如 你的域名.com/robots.txt),你通常会看到以下几行代码:
1. User-agent(你是谁?)
User-agent: *
星号 * 代表通配符,意思是“对所有搜索引擎爬虫生效”。
2. Disallow(禁止进入)
Disallow: /admin/
意思是禁止抓取 /admin/ 目录下的所有内容。这是用来屏蔽后台或隐私目录的。
3. Allow(允许进入)
Allow: /
意思是允许抓取根目录下的内容。通常配合 Disallow 使用,作为特例开放。
4. Sitemap(地图在这)
Sitemap: https://domain.com/sitemap.xml
这行非常重要!它告诉爬虫:“虽然我限制了一些地方,但你想找好东西,请看这张地图。”
四、 新手避坑:千万别犯这个错!
对于使用 WordPress 或 Shopify 建站的朋友:
- WordPress:插件(如 Rank Math)会自动生成虚拟的 robots.txt,通常是完美的,不需要你手动上传文件去覆盖。
- Shopify:官方默认配置已经很科学,屏蔽了购物车和结账页,你也改不了核心部分。
❌ 致命错误示范:
User-agent: *
Disallow: /
这就这多了一个斜杠 /,意思是“禁止抓取全站”。如果你不小心写成这样,你的网站就会在 Google 搜索结果里彻底消失。
总结
Robots.txt 是网站的规则制定者。
作为“一人公司”的运营者,你不需要亲自去写代码,但你一定要会“检查”。
现在,在浏览器里输入 你的域名.com/robots.txt,看看是不是能正常打开?有没有误封了重要页面?只要它是正常的,你的 SEO 地基就是稳固的。
发表评论